Any AI company will ultimately want to become a data company where it holds certain unique data that no one else in the world has access to. This means that the company needs to have a great database. At Tune AI we are building a high performance IDP that can consume millions of documents / day, organise that information and provide a retrieving method as an API (traditional) or agent (conversational).
Building the traditional APIs are easy, have a fixed schema and, put relevant indexes in your Postgres JSON columns and provide a Go server on top. For agentic workflows this changes to building a Retrieval Augmented Generation (RAG) flow. Where the information is indexed in both the structured way as well as in latent space with embeddings. And this latent space is a real challenge because currently we use embedding models with cosine similarity for searching.
Here's the simple question I have: "How to do a RAG based Q/A on 2,667,502 arXiv papers?"
Chunking
The first part in any RAG system is going to be chunking ie. breaking the document into small parts that are the building blocks of the incoming document. First let's talk about the raw data. Documents can be of many different types, technically there are as many types of documents as there are file types in a computer system. Think about it, we all know about the text based (.pdf, .pptx, .word) but so is audio (.mp3, .wav, .mp4) and so is video (.mov, .mkv). But that's not the limit, if you think more there is .psd for photoshop files, there is .dwg for CAD and 100s of other files in the long tail of file extensions.
Documents must be split into parts that have some meaning. When you look at a part it should make sense, just like when you look at a nail you don't know where it comes from but you know how it can be useful. There are some attributes like it is pointy and made of steel. Similarly, think of the Economic Survey of India Report, it is a PDF document with charts and images. When you look at a chart, you may not be aware where it comes from, but you know what it means. In the chart below you can understand what it is about.
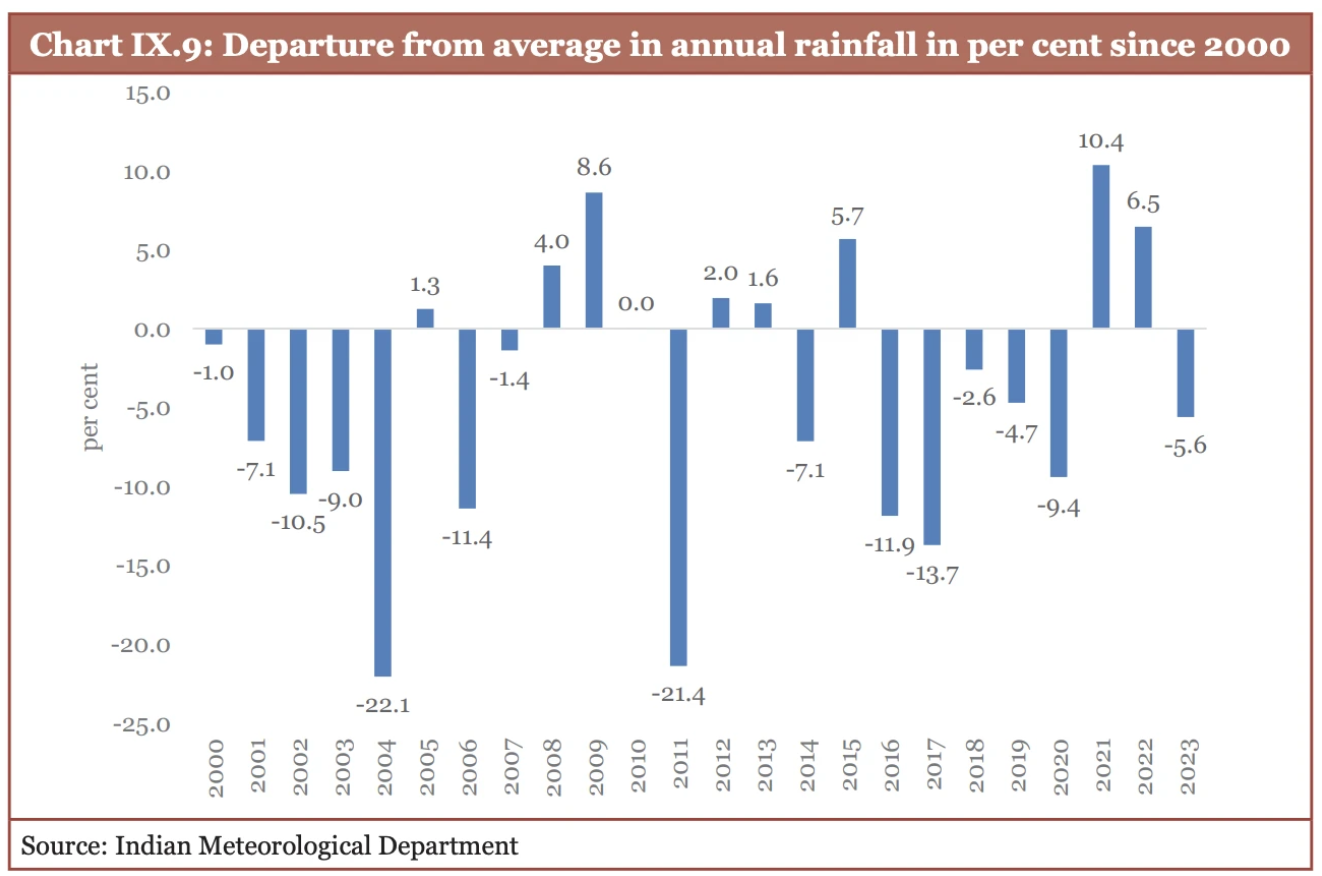
The chunking strategy you use should be smart enough to break apart the document into components like these. When your AI refers to this to answer a question it will not only be able to give a much better answer, but your user will be happy when they can see the chart for themselves. Ultimately everything is done to build a great user experience. For this I recommend using a VLM based model that can break apart the incoming documents into semantic chunks.
When parsing a table, it can be useful to store things like headers, number of rows, type of columns in one of the chunks of the table so AI can use this information without even having to read the table. Of course based on your use case you have to be smart and think what would be the best way to chunk any document.
Indexing
I'll come to my favorite part which is indexing of those chunks. In a normal embedding based cosine similarity RAG system indexing means putting the values in an array and storing it effectively on a disk. Most vector databases use HNSW to store values most effectively on the disk. However we are going to take a look at all the ways information is stored in the general world:
Books
For pretty much most of the history information was stored in the form of a book, first oral, then written. Books follow a simple structure:
- There is a broad topic to be discussed in the book
- A whole bunch of subtopics to be discussed
- there is a story (flow) to the entire book (This is probably most important yet highly disregarded)
- A table of contents to quickly jump across parts of the story
- Finally an index to jump across parts in the topics
We'll call the flow "story" for everything, not just fictional books. Let's take an example of a physics book:
- The topic can be "Mechanics of particles"
- Subtopics can be "Relativity", "Subatomic scales", "Newton's laws", etc.
- The story is stitches it together by talking about "Origins", "Newton's laws" and then "Relativity"
- The table of contents helps group all the sub topics together like "Ancient Times", "Mediaeval Times" and "1900s", etc.
- Index at the end of the book will refer to all the parts like tables or charts, specific equations, etc.
Now there are things that sit outside the book such as the subjects, complexity levels, purpose, etc. If you think about this, books are like Tree data structures and indexes are like pointer groups that help you go to specific locations in the tree fast.
Wikipedia
I'm going to skip over Encyclopedias and jump directly to Wikipedia because it solved the problem that books could not:
- It connected topics from inside the books and created as knowledge graph instead of bunch of trees
- Books are narrow/deep packets of information while wiki articles are wide/shallow which means it is easier to get a gist of what the topic is
- You can refer to multiple topics together like an encyclopedia
- It refers to sources and comes up with opinionated (debatable) notes about topics
Though there are links between each article, ultimately each individual article is a tree of (topic_key - content_value - subtopic_key) triplets.
B+ Tree
This is a popular storage system used in InnoDB and other databases. I don't claim to be an expert at databases so I'll just mention why I've put it here. B+ Tree storage and searching is fast because of the highly efficient indexes. Unlike parsing books and Wikipedia where the indexes are simple and based on the topic keys, the database indexes are based on the values. Of course no human can beat the computers yet even if you hypothetically build a system that traverses the knowledge tree by topics, it'll be slower because it uses key based searching instead of value based searching. This argument can be called dumb but I'll still keep it here.
Moreover the index is adaptable for speed. If a node is deleted then the entire tree can be reorganised to give a better performance. This is completely different from a Knowledge graph where changing an information requires detecting all the places and modifying them. E.g. if tomorrow we realise that there are indeed 15 planets in our solar system. Finding all the 1000s of articles that mention 8 planets and rewriting those would be a tremendous hassle.
Putting it together
I've covered three storage systems that are my inspiration. Now I want to give my thoughts about what constitutes a good indexing system for RAG.
-
First the data should be stored hierarchically because some topics are more broad than others. This is the biggest mistake with current systems which treat every piece of information equally useful. In cosine similarity there are only two values, the incoming query vector and values matrix. There is no concept that some things are more important than others. In theory this implies that there is a missing key vector that can help with the attention.
-
Second, as much as possible metadata be indexed in a schema. In the end your data is going to be stored in some kind of database, searching, sorting, filtering will always be required. Having a schema helps your AI filter things fast, e.g. if a user says "Give me all the charts showing this", it would be much faster to filter the chunks that contain charts. Again this schema has to be defined and based on your use case. In case of arXiv research papers we already know the categories.
-
Third, have interfaces with third party storage. You (or your startup) are going to have every piece of data for your use case. AI is anti-entropy technology and it means it will keep collecting more information and organising that. There will be data that needs to be fetched from elsewhere, e.g. user asks "find me relevant papers like this" then your system has to be able to search arXiv, WoS or Google Scholar. This means your software should not only be able to interact with that information, it should also be able to store the once collected information.
There are many more things but I'll cover those sometime else. In essence your indexing algorithm should be such that it provides the right tradeoffs between speed, depth, width and adaptability (because the world keeps changing).
Querying
Querying is the process of going over the index to find relevant information and returning those in a streaming fashion.
As explained in the previous section, current embedding systems treat every information as equal, completely discounting natural hierarchies. Maybe one day there will be an embedding model that perfectly captures that information. However the algorithms used today are approximate nearest neighbours (ANNs) and they are not perfect.
Another aspect is searching non-stop. The AI systems are designed to run non-stop and keep digging through things to find answers. Unlike a Google Search which ends once it has returned you with results, AI systems want to consolidate more information which means it should be able to navigate the search space like humans. If you find an interesting link, go read it, click on a link on that page, go back to Google, go to another link and so on. All this while AI should keep collecting the information and storing it for future use. In a flat storage system you can be sure that once the first few items have been checked new items are going to be less relevant.
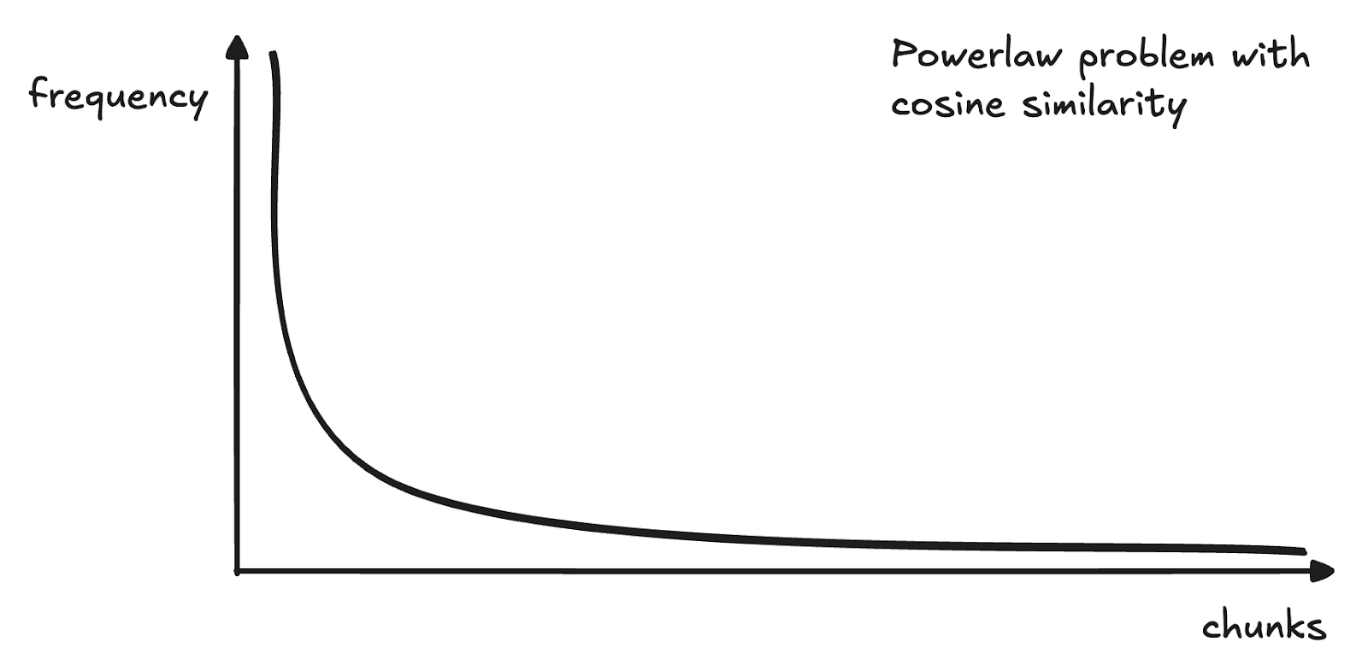
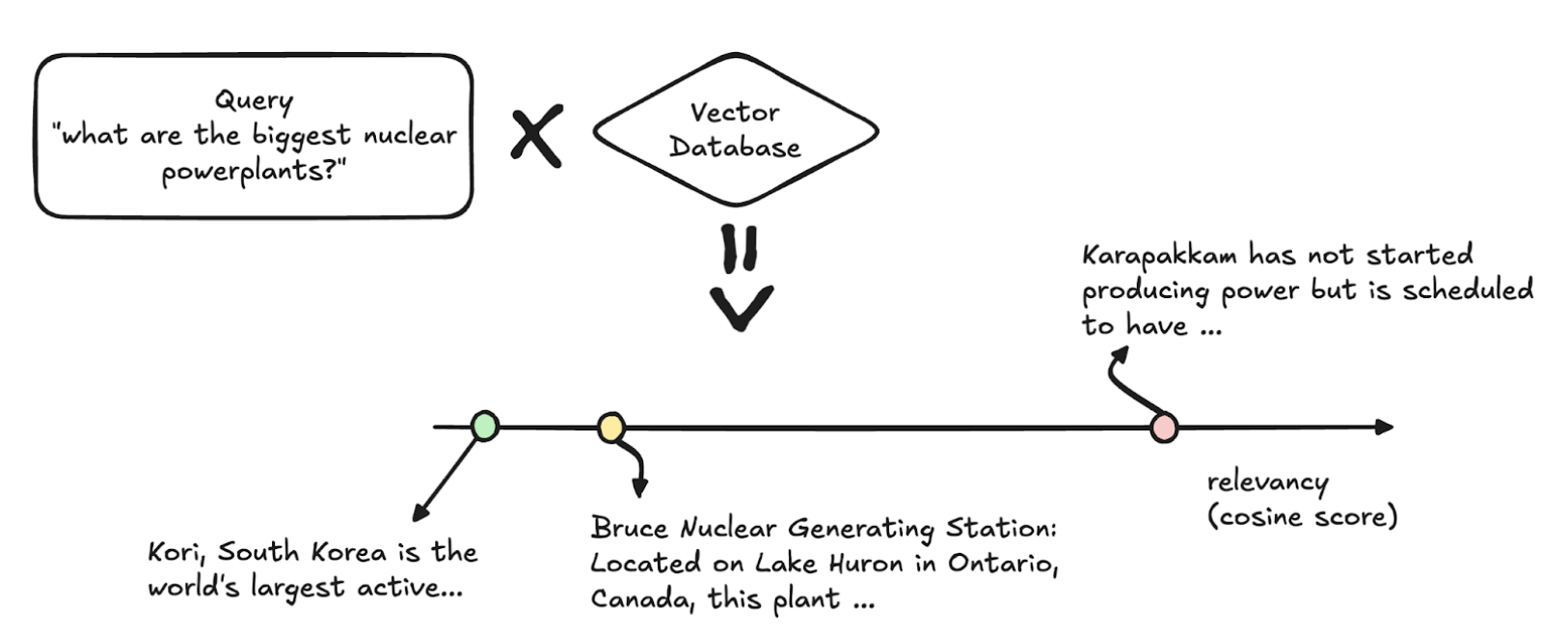
Due to the nature of cosine similarity there will be some chunk vectors that are always going to be more similar to others. This means that not only are some chunks more referred than others. This can create outliers that are not considered. In the example below let's say we query for "nuclear power plants", the sentences that contain the word "nuclear" are more similar however any human with knowledge can tell that places can also refer to such power plants.
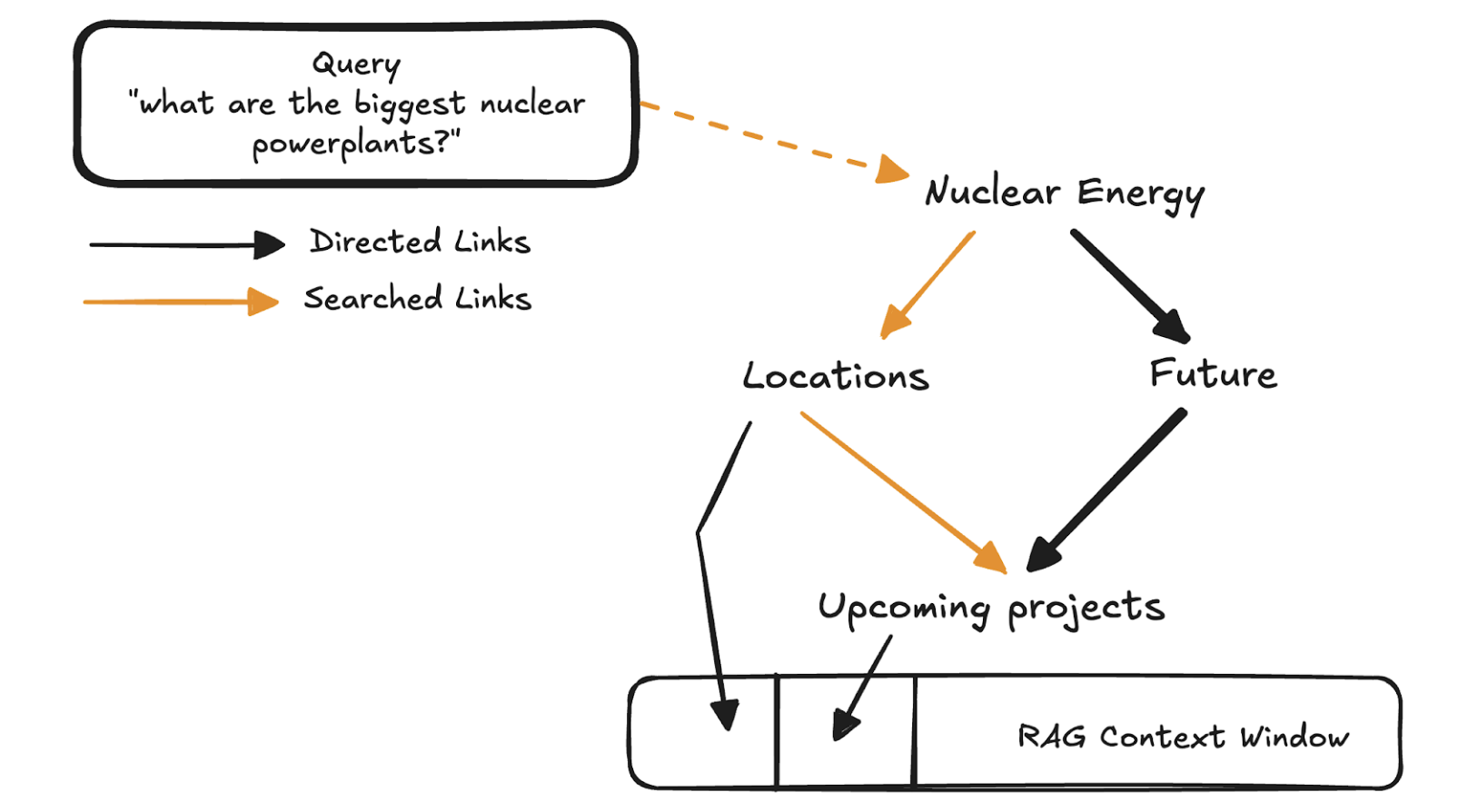
If there was a hierarchical storage, the agent could have traversed over the search space to continuously improve the RAG context window. This not only would have allowed it to search things faster at the higher level but also go deeper into any topic.
One clear drawback to this approach because it implies that there is an index already present before querying. What happens when there is a document thrown at realtime? For this we can always fallback to an embedding based system which will actually work better since the search space of a document is smaller than all 2.6Mn documents.
I now want to conclude this because I've been writing non-stop for 3 hours and I should get home. I will follow up more on the journey of building the IDP platform that can scale to processing 1 Mn+ documents/day and to RAG on those.